
How RAG Transforms AI from Chatbot to Personal Assistant 🔗
Traditional LLM systems face a fundamental limitation: they only know what they learned during training. This creates a knowledge gap that grows wider each day as new information emerges. Retrieval Augmented Generation (RAG) solves this problem. It gives AI access to real-world, real-time information.
RAG transforms a basic chatbot into a knowledgeable personal assistant. It retrieves relevant context before generating answers. This results in more accurate responses with fewer hallucinations.
How RAG Works 🔗
The RAG process follows three simple steps:
- User asks a question - The system receives your query
- System searches for context - Instead of generating an immediate answer, it searches for relevant documents
- AI generates informed response - The system combines your question with retrieved documents and sends both to the language model
This approach ensures the AI has access to specific, relevant information before crafting its response.
Note thate “system” here means not only the LLM. Usually you will have a (thin) layer on top of your LLM plus a datasource for context (i.e., a vector database). This layer handles the search for context and combines it with the original question. This might be a small backend service. See the simple retrieval workflow below for clarification:
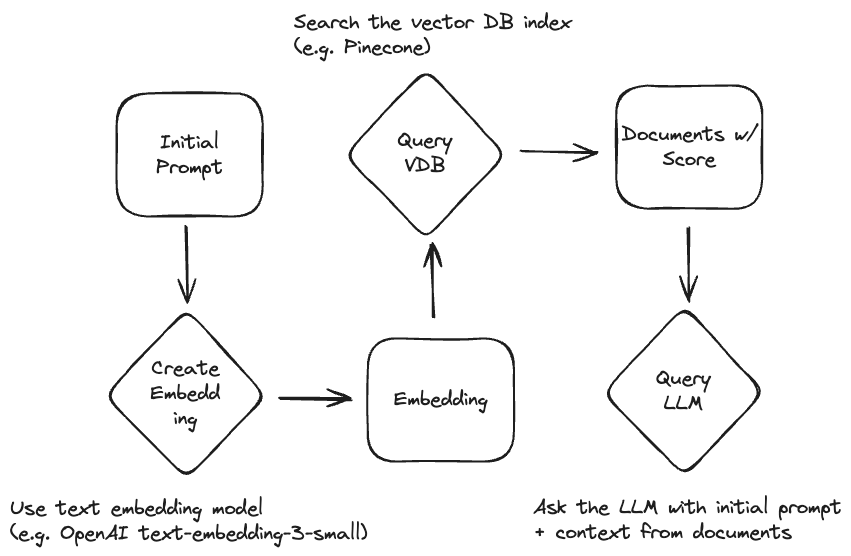
The Foundation: Vector Databases 🔗
Vector databases power RAG systems through a sophisticated process:
Embedding: converts text into numerical vectors that capture meaning and context. These high-dimensional numbers represent language in a way computers can understand and compare.
Retrieval: uses your prompt to search the database for semantically similar documents. Unlike keyword matching, vector search understands relationships between concepts. It knows that “heart attack” relates to “cardiac arrest” even when exact words don’t match.
Context delivery: combines your original prompt with the most relevant retrieved documents. Thus giving the AI everything it needs to provide an accurate answer.
One example, which is free to experiment with, would be Pinecone.
Document Preparation: The Critical First Step 🔗
The quality of your RAG system depends entirely on your data. Even the most advanced AI model produces weak results when fed poor context. Garbage in, garbage out.
Chunking Strategy 🔗
Good chunking improves retrieval quality. You have several options:
- Fixed-length chunks - split documents into consistent sizes (e.g., around 500 words)
- Token-based splitting - creates chunks of tokens (e.g., 300–500 tokens)
- Section-based chunks - follow natural document structure like paragraphs
Chunks can overlap to preserve important context that might span boundaries. Strategic chunking means more accurate retrieval. But poor chunking leads to noisy or irrelevant responses.
Humans Still Welcome 🔗
Human expertise remains essential for RAG success. You need a subject-matter expert that should:
- Clean up documents and ensure accuracy
- Remove misleading information
- Organize data logically
- Update content regularly
- Cut bias and inconsistencies
Without expert review, adding context can backfire and make your AI less reliable.
Implementation Process 🔗
Setting up RAG involves two main parts:
- Document ingestion - Allow users to upload and manage their documents
- Vector database setup - Store embedded documents for fast retrieval
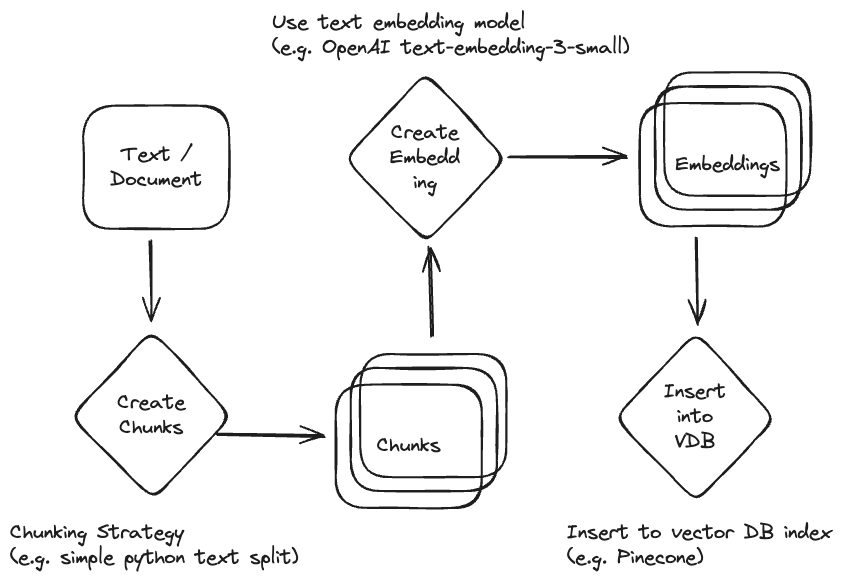
The system chunks documents, generates embeddings for each chunk, and stores them in the vector database. When someone asks a question, the system embeds that query and finds the most relevant chunks through mathematical distance measurements. See the simple ingestion workflow below for clarification:
Simple Ingestion Workflow 🔗
The Business Impact 🔗
RAG delivers three key benefits:
- Knowledge gap filling - Your AI can access information it never learned during training
- Trust building - Users gain confidence when they see AI responses backed by specific sources
- Personalization - Each organization can customize their AI with proprietary data and domain expertise
Making It Work 🔗
Strong embeddings and thoughtful chunking directly improve your AI’s performance. When you give your model the right context at the right time, it delivers more accurate, reliable, and useful responses.
The key insight: RAG succeeds by feeding proprietary data into your AI’s knowledge base through intelligent retrieval. This approach transforms static AI models into dynamic systems that grow smarter with your organization’s unique information.
Vector search and semantic understanding work together to bridge the gap between general AI capabilities and specific business needs. The result is an AI assistant that truly understands your domain and delivers relevant, actionable insights.